
• Filed to: OCR PDF Dateien • Proven solutions
"Ich habe eine gescannte PDF-Datei, die eine Tabelle mit etwa 200 Nummern hat. Ich muss all diese Zahlen herausnehmen. Gibt es eine Möglichkeit für mich, die Zahlen in einer einzigen Datei zu extrahieren?"
Wie wir alle wissen, gescannte PDF auch bekannt als Image PDF enthält Reihe von Bildern, die zusammen, um ein einzelnes Dokument für das Lesen und den Austausch zusammengeführt wurden. Um Texte aus einem gescannten PDF zu extrahieren, müssen wir die Datei in ein editierbares Format konvertieren, indem wir ein PDF-Konvertierungstool mit OCR-Funktion verwenden. Hier sind die besten zwei Möglichkeiten, dies zu tun.
PDFelement ProIn vielen Fällen müssen Sie die gescannte PDF-Datei vor dem Konvertieren bearbeiten. Wenn ja, können Sie verwenden PDFelement Pro als der OCR-PDF-Editor und Konverter. Mit diesem leistungsstarken PDF-Tool können Sie Texte, Links, Bilder und andere Elemente in gescannten PDFs bearbeiten, hinzufügen oder löschen. Und Sie können sogar das gescannte PDF in Excel, Word, PPT und andere Formate konvertieren.
Im Folgenden finden Sie detaillierte Schritte zum Konvertieren von gescannten PDF-Dateien in Excel zur weiteren Bearbeitung im Mac OS X (einschließlich macOS Mojave 10.14). Und Sie können mehr PDF-Lösungen zu überprüfen hier.
Wenn der Herunterladen und die Installation abgeschlossen sind, können Sie auf die Schaltfläche "Datei öffnen" klicken, um PDF zu laden. Wählen Sie die gewünschte Datei aus dem lokalen Ordner aus, und klicken Sie dann auf Öffnen, um Ihre Auswahl zu bestätigen.
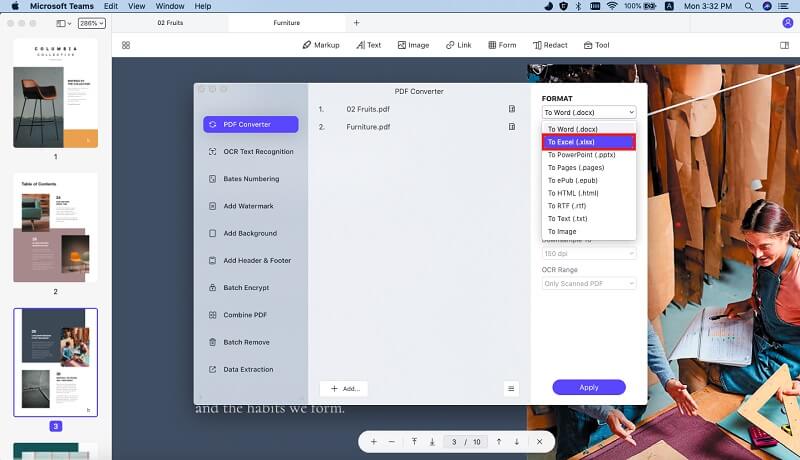
Dann müssen Sie auf die Schaltfläche "Konvertieren" in der oberen rechten Ecke der Schnittstelle klicken. Klicken Sie auf das Symbol "W" und wählen Sie "Excel" aus der Liste der Ausgabeformate. Schalten Sie die Taste "OCR" ein. Klicken Sie dann auf "Konvertieren", um PDF zu Excel OCR-Konvertierung zu starten.
Warum wählen Sie PDFelement Pro:


Alexander Wagner
staff Editor