Los 3 Mejores Programas OCR de Código Abierto

• Filed to: OCR archivo en PDF • Proven solutions
OCR es el método para convertir un archivo de texto que no es editable. Hablando con ejemplos, el OCR es capaz de convertir una página de un documento o similar en un documento de texto totalmente editable que puede ajustarse, buscarse y manipularse como un archivo de texto normal. Como podrás imaginar, esto puede ser extremadamente útil en muchas situaciones, así que ya estarás preguntándote cómo conseguir un OCR de código abierto. Tiene la ventaja de ser gratuito y fácilmente disponible en múltiples plataformas, pero ¿es la solución ideal si necesitas convertir páginas de un libro escaneado en páginas editables?
- Parte 1. Los 3 Mejores Softwares OCR de Código Abierto
- Parte 2. Cómo Realizar OCR a un PDF Escaneado
PDFelement Pro - La Mejor Herramienta OCR para PDFs


PDFelement Pro cuenta con una función OCR avanzada que te ayuda a editar y convertir archivos PDF escaneados y basados en imágenes. Es compatible con varios idiomas OCR para que te sea más cómo manejar archivos PDF.
Por Qué Elegir Esta herramienta OCR:
- Función OCR avanzada con varios idiomas.
- Edita y marca fácilmente archivos PDF.
- Convierte PDFs a otros formatos.
- Crea formularios PDF y PDF con facilidad.
- Protege PDFs con contraseña, marca de agua y firma.
Parte 1. Software OCR de Código Abierto Recomendado
#1. Tesseract
Tesseract es un maravilloso software de código abierto que Google mantiene actualmente. Se puede usar en varias plataformas, incluyendo Linux, Windows y OS X. Incluye soporte para varios idiomas, y tiene la capacidad de descargar aún más a través de extensiones. Sin embargo, es algo complicado en términos de uso y para obtener lo mejor de él, necesitas una cierta comprensión del código subyacente. Sin embargo, produce resultados precisos y con ese soporte multi-plataforma puede resultar útil en una amplia variedad de situaciones. Es bastante complicado aprender a usar el software, pero es muy potente.
#2. GOCR
Este es otro paquete de código abierto diseñado para ejecutarse en plataformas Linux, Windows y OS/2, proporcionando una gran variedad de opciones para casi cualquier situación. Al igual que con otros ejemplos de código abierto de software OCR, el proceso es preciso y el paquete se puede expandir, sin embargo, sufre de problemas similares con la usabilidad. Esto varía un poco dependiendo de la plataforma que se está utilizando, con algunos que tienen un usuario más amigable frontal que otros, sin embargo, sigue siendo una herramienta capaz una vez en uso.
#3. Cuneiform
Originalmente, una solución de OCR comercial, Cuneiform fue convertido a código abierto por su desarrollador cuando el desarrollo del proyecto cesó. Por esa razón, no es la solución más actualizada que hay entre las disponibles, pero es eficaz. Este es un software multi-idioma que sigue funcionando bien a día de hoy, y debido a sus raíces comerciales se las arreglan para evitar algunos de los escollos de otras soluciones de código abierto, como la interfaz de usuario intuitiva, etc. es el más fácil de usar de los tres. Con múltiples formatos de salida y un montón de personalizaciones posibles, es una buena pieza de software.
Comparación de los Softwares OCR Anteriores
|
Características |
Tesseract |
GOCR |
Cuneiform |
|---|---|---|---|
|
Sistema Operativo Compatible |
OS X, Windows, Linux | Windows, Linux, OS/2 | Windows |
|
Idiomas |
12 (más expansiones) | 2 | 20 |
|
Conversión de Archivo |
Forum/Mailing List | Mailing List | No |
|
Soporte |
No | No | No |
Veredicto:
No hay duda de que estos paquetes de código abierto ofrecen una forma de realizar OCR en sus documentos, sin embargo, todos ellos carecen un poco en algún lugar, ya sea la facilidad de uso o estar un poco obsoleto y no aprovechar al máximo los procesadores multicore de hoy en día para la velocidad . Con esto en mente, muchas personas recurren a paquetes comerciales más completos para satisfacer sus necesidades de OCR, y con un soporte completo, facilidad de uso y confiabilidad, no es ninguna sorpresa realmente. Los productos de código abierto tienen su lugar, pero para muchos confiar en las herramientas y necesitar algo que es un poco más fácil de ejecutar, los costos son muy a menudo bien vale la pena a largo plazo.
Parte 2. Realizar OCR con PDFelement Pro
Realizar OCR con PDFelement Pro
La función OCR avanzada de PDFelement Pro te ayudará a realizar OCR a tus archivos PDF fácilmente. Sigue los siguientes pasos:
Paso 1. Abre el programa
Después de abrir el programa, haz clic en "Abrir Archivo" para importar el archivo PDF escaneado al softwarte. Recibirás una notificación indicando que el archivo es un PDF escaneado.
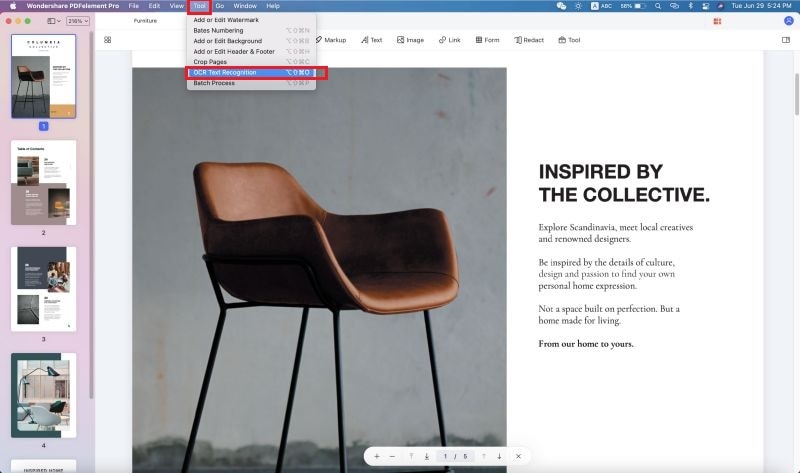
Paso 2. Realiza el OCR
A continuación, puedes hacer clic en el botón "OCR", debajo del botón "Editar". Puedes abrir el panel OCR en el lado derecho de la interfaz del programa. Ahora puedes personalizar el rango de páginas y el idioma OCR. Y luego haz clic en el botón "Realizar OCR" para aplicarlo al PDF escaneado.

Florencia Arias
staff Editor