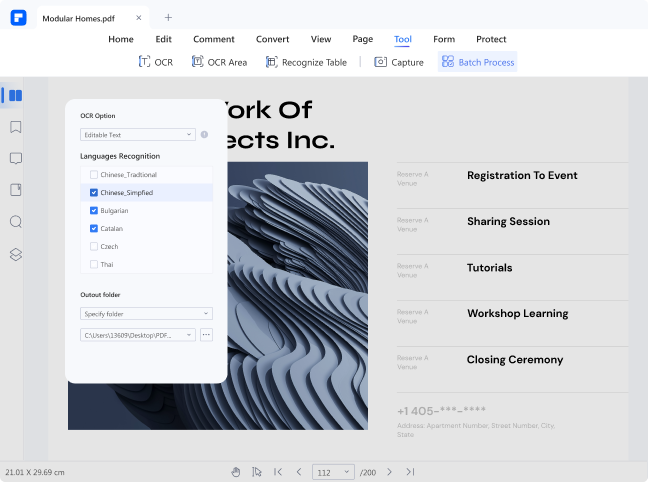
OCR - Convert Scanned
Files to Editable Ones
- It allows users to you want to edit scanned images or PDFs with just a single click. Thanks to the accurate text recognition feature.
- PDFelement gives a platform to extract target texts from image-based PDF files and use it for other formats.
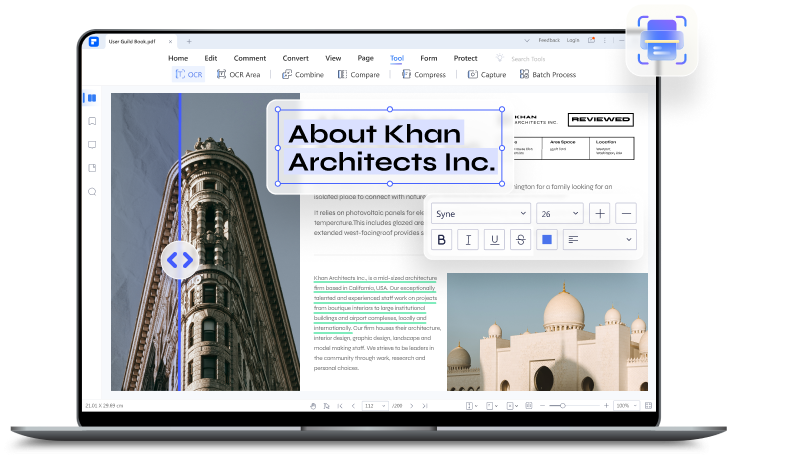

What is OCR
OCR is an acronym for Optical Character Recognition. This technology is highly used across the globe to recognize texts in images. So if you have scanned PDFs or images, you can recognize texts inside them.
Edit Scanned PDF
Once your document undergoes OCR, PDFelement makes the texts inside the images editable. You can edit existing texts and even add new texts on the scanned PDF or image and maintain the original text fonts.
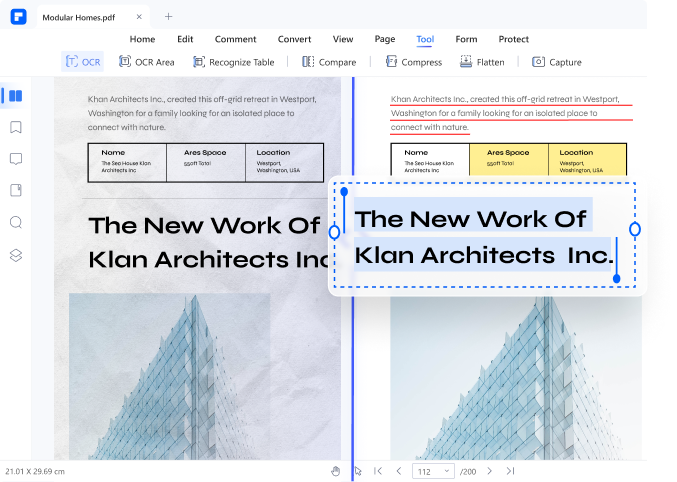
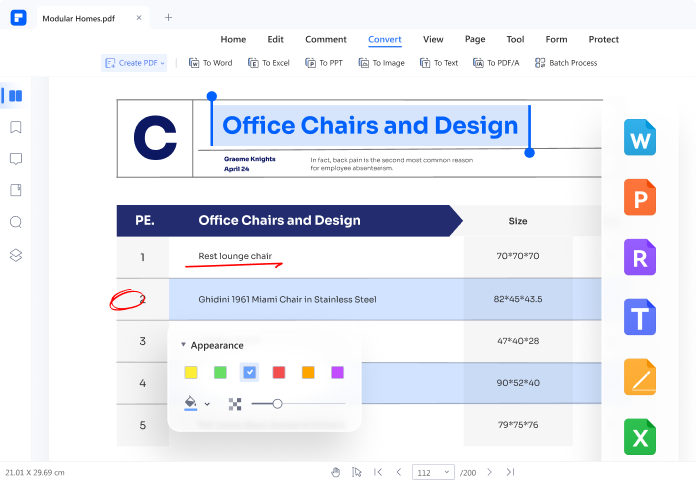
Convert Image to Text
The OCR feature in Wondershare PDFelement allows users to convert images or scanned PDFs into editable, selectable, and searchable formats. Your image-based PDF will resemble Microsoft Office documents, TXT files, PPT, or Pages.
Extract Data from
Scanned PDF
If you are struggling to manually extract data from your image-based PDF, PDFelement will end this. With PDFelement's OCR feature, you can select and extract desired text regions or simply extract target content from PDF form fields.
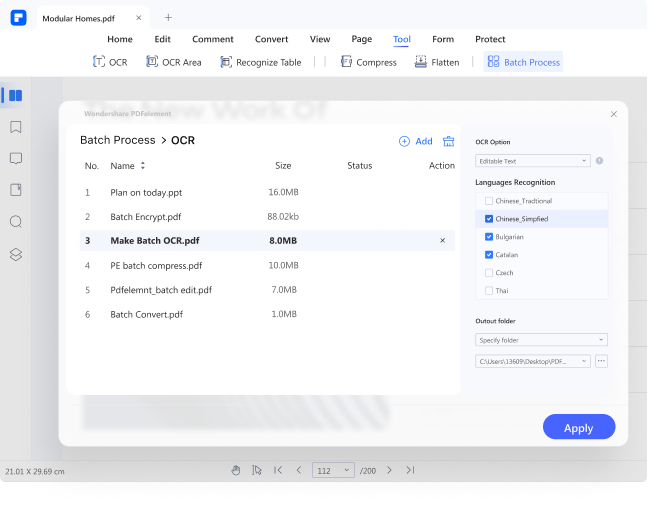
Batch OCR
It might prove tricky when you have multiple image-based PDF files, yet you want to search some content across those files. Fortunately, PDFelement supports batch OCR. This amazing feature allows you to convert image-based PDFs into editable and searchable PDFs simultaneously.
Recognize 20+ Languages
The PDFelement's OCR feature can recognize texts on image-based PDFs across different languages. These languages include English, Japanese, Portuguese, Spanish, German, Italian, Croatian, Latin, Bulgarian, Chinese Traditional, French, and Chinese Simplified, just to mention but a few.